Doccano is an open-source annotation tool for text data, designed to facilitate the creation of labelled datasets for natural language processing (NLP) tasks. It provides a web-based interface for annotating text, making it easy to create datasets for tasks such as text classification, sequence labelling, and sequence-to-sequence tasks.
Doccano components
- Web-based interface: An intuitive graphical interface for annotating text data, accessible through a web browser.
- Backend server: Manages data storage, user authentication, and interaction with the annotation interface.
- Database: Stores annotated data, user information, and project details.
- API: Provides endpoints for managing projects, users, and annotations programmatically.
- Authentication system: Supports user authentication and role-based access control for collaborative annotation projects.
Features
- User-friendly interface: Intuitive and customisable UI for efficient text annotation.
- Multi-task support: Supports text classification, sequence labelling, and sequence-to-sequence annotation tasks.
- Collaboration: With role-based access control, multiple users can work on the same project.
- Project management: Create and manage multiple annotation projects with ease.
- Export functionality: Export annotated data in various formats, including JSON, CSV, and more.
- Customisable labels: Define and use custom labels tailored to specific annotation tasks.
- Real-time progress tracking: Monitor annotation progress and project statistics in real-time.
Use cases
- Text classification: Annotate text data for classification tasks such as sentiment analysis, topic categorisation, and spam detection.
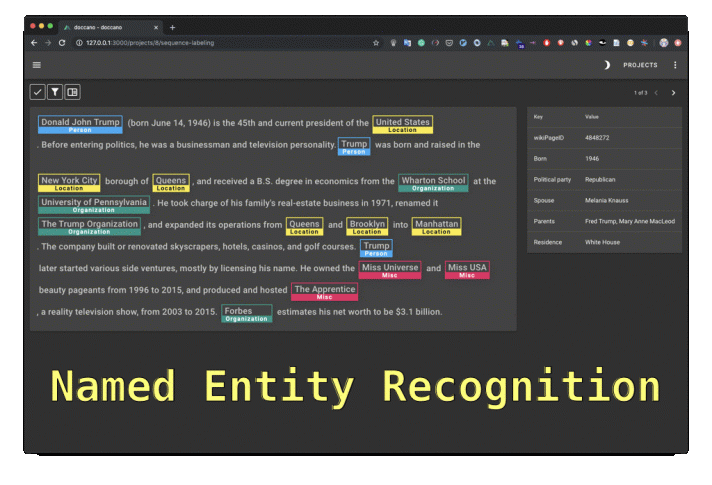
- Named Entity Recognition (NER): Label entities in text for NER tasks, including person names, organisations, dates, and more.
- Part-of-speech tagging: Annotate parts of speech in text data for syntactic analysis.
- Sequence-to-sequence tasks: Annotate data for translation, summarisation, and other sequence-to-sequence tasks.
- Custom NLP tasks: Create datasets for specialised NLP tasks based on custom annotation needs.