
Rome wasn’t built in a day. The same is true for data foundations of government organisations. Yet, cities, regional agencies and ministries constantly seek the fastest ways to keep up with the latest data trends. Urged by rising societal demand, they feel their organisation cannot miss out on these developments. But how can civil servants implement the latest technologies when the work on the ‘buzz words’ from a few years ago has just started? Does the endless rise of data trends distract governments from embedding actual data solutions?
Early adaptors that managed to reap the benefits of (Big) Data may already lag in the quest for Machine Learning, Large Language Models and (Generative) AI. Those who start to master their Open Data and Linked Data practices may also take part in the race for data sharing and data spaces. Realising data value requires predictive analytics and moving towards real-time analytics based on billions of connected IoT devices. Furthermore, data hosting and storage developments keep governments puzzled, finding themselves in a cloud transition.
Not all public administrations seem ready to implement the latest data solutions. They would first need to focus on establishing a more solid basis. One way to prepare for ongoing data waves and build these infrastructures is to demonstrate what value data can bring rather than jump on the next trend, which will likely be replaced by another one not far from now.
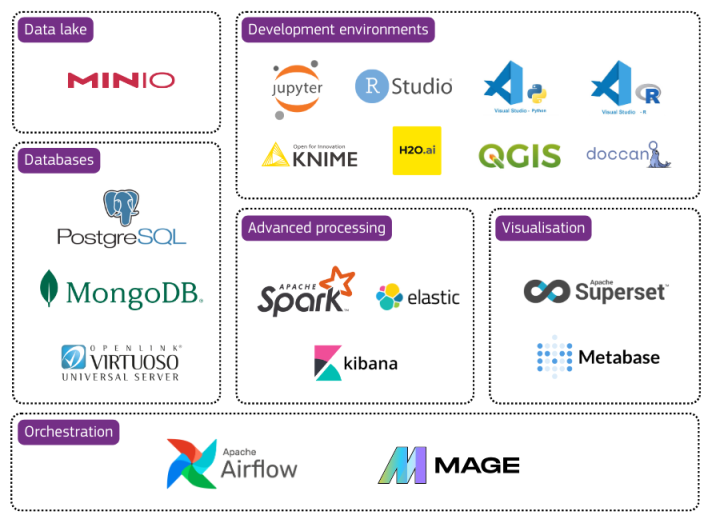
The European Commission provides data services to establish more robust data foundations, enabling future data megatrends: the Big Data Test Infrastructure (BDTI). The BDTI offers public administrations a diverse and complete set of open-source tools for data storage, processing, and analytics hosted in the cloud and free of charge. It is available to civil servants at all levels of government in Europe to autonomously run pilots, demonstrating the value data can bring to societal and policy challenges. Civil society, academia, and the private sector can join Big Data Test Infrastructure pilots, too, if a public administration body is at the centre of the use case. Within BDTI’s 6-months pilot, participants can learn all about the value of using data in their sector and what it takes to become a more data-driven organisation.
This article will present an example use case after a general introduction to the BDTI service and its characteristics. It demonstrates how various open-source tools can prepare the public sector for future data waves.
The EU Big Data Test Infrastructure: What It Is and How It Works

The Big Data Test Infrastructure (BDTI) was created by the European Commission in 2019 and has been enhanced ever since. It is part of the Digital Europe Programme (DEP), which aims to shape the digital transformation of Europe’s society and economy. As a key building block, BDTI increases the easy availability, quality and usability of public sector information in compliance with Open Data Directive requirements.
The Big Data Test Infrastructure aims to foster the re-use of public sector data and enable a data-informed public sector in the EU Member States. By providing a free-of-charge analytics test environment with open-source tools, the BDTI allows public administrations to prototype solutions before deploying them in the production environment on their premises. The BDTI applications are a cloud service enabling users to experiment with data in a pilot project. Pilots address a clear and well-scoped (policy) challenge that data can address.
Demonstrate Value Before the Next Data Hype Arrives
In the following sections, we will walk you through a fictional BDTI pilot at the Municipality of Dublin, which clarifies how the BDTI’s capabilities and tools can be applied to generate valuable insights from data. It starts with the vital question: “How could the city of Dublin save energy and expenditures by optimising its traffic lights schedule?”. All project components are open source and available on the European Commission GitLab, allowing for re-use. The BDTI Value Demonstrator use case consists of three stages typical of a data science project:
(1) Data Ingestion: ensuring the correct type of (machine-readable) data is gathered, cleaned and available.
(2) Visualisation & Analysis: turning data into insights by visualising different data components and analysing relationships between data elements.
(3) Decision-Making: making data actionable to create value for public administration's internal and external stakeholders.
The Dublin use case is based on open data where possible but also contains fictional internal data. Government spending data for Dublin comes from data.smartdublin.ie, while government spending data for the reference cities are fictional. Historical traffic data comes from data.gov.ie, and the weather forecast is sourced from open-meteo.com. The GitLab page for this use case is open and visible to anyone who wishes to see the complete documentation, including user guides and scripts needed to replicate it, as well as the details regarding the (open) datasets used. In the first two steps of this use case, the BDTI’s tools are used to ingest and visualise government spending data. In the last step, we use machine learning techniques to build a data solution to reduce spending on public lighting.
Data Ingestion: Generating Machine-Readable Data to Start the Generative AI Engine in the Cloud?
Large Language Models and Generative AI rely on high volumes of machine-readable data. But how do you establish big sets of high-quality data when your initial data is unstructured and hidden? For example, your government data consists of thousands of paper forms, written information, and printed archives.
The first step of the Dublin use case is ingesting the government spending data. The specific challenge that needs to be addressed relates to the energy invoices, which are only available in PDF format in our scenario. These non-machine-readable PDF invoices must be transformed into data that can be easily processed later. A solution is built using KNIME, a tool available on the BDTI. KNIME stands for KoNstanz Information MinEr and is open-source software with an intuitive visual interface that does not require coding. The tool includes Optical Character Recognition (OCR) features. OCR is the technology that interprets human-readable documents and transforms them into machine-readable data. The output table can be reused to process and analyse the data further. We used PostgreSQL, a relational database system, to store the output data in preparation for the next step.
Moreover, many organisations wonder where to store their data and how to govern it effectively. The Irish use case data is stored on the BDTI cloud services. For actual pilot participants, this analytics cloud stack is free during the 6-month completion of a use case. The European Commission provides the capacity for hosting large volumes of data, on which public administrations can test various types of analysis. The platform offers the required cloud infrastructure, including virtual machines, analytics clusters, storage, and networking facilities. Visit the service offering page to learn more about the available tools. After completing a BDTI pilot, users can take the source code and data to continue the work using the cloud of their choice or other resources.
Visualisation & Analysis: Solid Visualisations to Pave the Way for Real-Time Analytics?
After completing the data ingestion, the next step is visualising and analysing the data, in this case, Dublin’s government spending. We use the open-source tool Apache Superset, a data exploration and visualisation tool available on the Big Data Test Infrastructure.
The result is a dashboard that visualises Dublin's government spending data by presenting the proportion of spending for each category relative to the total expenditure. Although this information is interesting, it does not help us understand whether spending is high or low.
To provide more context to Dublin’s government spending data, we compare Dublin’s spending against two similar (fictional) reference cities. This comparison reveals that Dublin allocates a relatively large portion of its budget to public lighting. This kind of benchmarking will not directly tell us where Dublin spends too much or too little but can give us hints about what to investigate further.
Ideally, the visualisations and analytics are updated in real time. For example, showing real-time traffic flows and weather conditions using large numbers of sensors and connected IoT devices to regulate traffic lights automatically. However, for cities that do not have the data foundations in place to work with real-time data, the static data already provide key insights to move forward. By showing the value of the static data first, one’s organisation is also more likely to invest in such a next step. The experience from building the use case will allow for more targeted approaches and more effective use of resources.

Decision-Making: Collaborate on a Data Pilot for Building Future Data Spaces
New data innovations often require significant levels of internal and external cooperation. At the same time, not all public sector bodies are able or willing to start their data sharing and common data spaces journey. How can you use a BDTI pilot to test your collaboration and joint decision-making skills?
The third and last step of the use case aims to build a solution for data-informed decision-making on public lighting related to expected traffic levels. We used three open-source tools available on the BDTI to build this solution: Jupyter Notebook, PostgreSQL and Apache Superset. Thanks to this combination of tools, we could build a solution that supports civil servants in achieving savings on public lighting. To reach a solution, we first used Jupyter Notebook to train a machine-learning model that predicts traffic for the upcoming week. Jupyter Notebook is a tool for creating and sharing documents that contain code, visualisations, and text. The tool can be used for data science, statistical modelling, and more. The machine learning model that we built uses weather data and traffic data, requiring the processing of large volumes of data. The BDTI is intended to process big data, so it will support you in processing very large datasets like these.
After training and running the machine learning model in Jupyter Notebook, the output data are stored in PostgreSQL. Apache Superset uses the data for the visible part of our solution: the dashboard that supports civil servants in achieving savings from public lighting. The dashboard allows users to analyse savings that result from turning off public lighting when light is least needed. To determine when and where lighting is least needed, we use the predicted traffic levels as a proxy for activity in the street. The lower the activity in a street, the less need for lighting.
The Big Data Test Infrastructure allows for authorising access to multiple teams from the same or different organisations. While the data remains secured, cooperation could enrich the data and pilot outcomes. In the case of Dublin, this entailed collaboration among the Department of Transport, the Department for Economic Affairs, Finance & Budgeting, and professionals from the Energy and Sustainability department. This demonstrates that multiple governmental departments can collaborate on a BDTI pilot project, or a partnership could involve a university, GovTech company, and public administration. BDTI also allows for developing a use case across borders, for instance, by teaming up Dublin with the city of Budapest.
Real Success Stories and Use Cases for Real Data-Driven Governments
To demonstrate the practical implementation of the platform, the European Commission showcases several real-life success stories. Additionally, the BDTI website provides multiple use cases that showcase the platform’s capabilities based on open data. For example, the search analytics use case is based on the CORDIS open dataset, and the low code analytics use case works with the EMHIRES open dataset on solar power generation.
Are you a civil servant interested in developing your data use case on the Big Data Test Infrastructure? Are you ready to prepare for the next data trend, gain experience and better decide on what data innovations are relevant to your public administration? Apply for a BDTI pilot project or contact the BDTI team via EC-BDTI-PILOTS ec [dot] europa [dot] eu (EC-BDTI-PILOTS[at]ec[dot]europa[dot]eu) to discuss your organisation’s data needs and embrace the next generation of data trends.
ec [dot] europa [dot] eu (EC-BDTI-PILOTS[at]ec[dot]europa[dot]eu) to discuss your organisation’s data needs and embrace the next generation of data trends.
Details
- Publication date
- 25 April 2024
- Author
- Directorate-General for Digital Services