
Self-paced labs are short tutorials developed using Jupyter Notebooks for an interactive learning experience. Users can read the text explanation and directly run the relevant Python code snippet. These short tutorials introduce BDTI users to popular Python Frameworks for Data Science use cases, and use open source data from data.europa.eu and Kaggle (an open source machine learning community) to demonstrate these Python Frameworks.
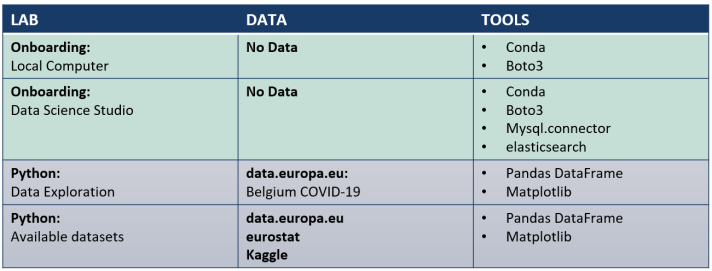
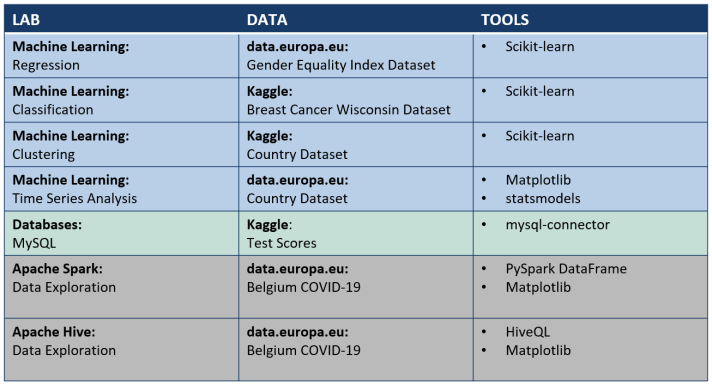
An overview of the available self-paced labs is provided in the table above.
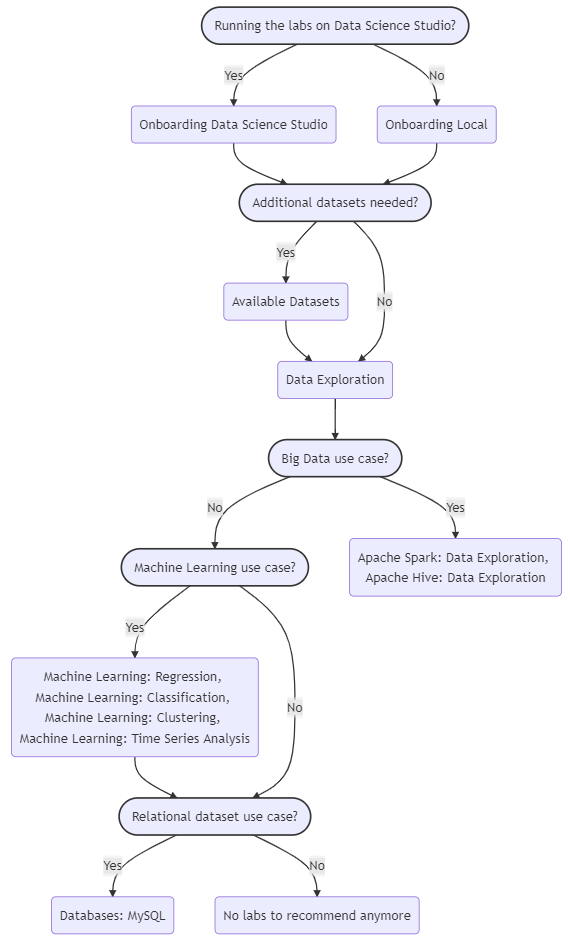
The above decision tree recommends which available self-paced labs you should consult based on your use case:
- As a first step, we recommend to go though the lab Onboarding: Data Science Studio if you are running Jupyter Notebooks on your Data Science Studio. This lab explains how you can, e.g., programmatically connect to other resources in your infrastructure. We recommend to go through the lab Onboarding: Local for any other Jupyter Notebook environment (e.g. on you local computer). This lab explains how you can, e.g., upload your data from your local computer to the S3 bucket of your infrastructure.
- If you would like to explore other datasets with similar use case as yours, we recommend to go through the lab Available Datasets. This lab explains how you can consult open source data of data.europa.eu, eurostat, kaggle, etc, and how to download their datasets programmatically.
- We recommend to go through Python: Data Exploration. This lab explains how you can use Python to import your data in Jupyter Notebooks, preprocess your data and how to preliminary analyze your data.
- Big Data use cases usually are characterised by the "three Vs of Big Data": Data that has high volume (e.g., data above 30 GBs), data that has high velocity (e.g., streaming requirements), data that has high variety (a high variety of different data sources). If your use case involves Big Data, we recommend to go through the lab Apache Spark: Data Exploration or Apache Hive: Data Exploration, depending on the framework you would like to use.
- Relational datasets are often represented using tabular format (using rows and columns) and static schemas (static naming to the columns of the tabular format). Relationships between columns can be described using diagrams with the help of primary keys and foreign keys. A sophisticated software system used to maintain relational databases is called a relational database management system (RDBMS). If your dataset is not relational of nature, it is called a non-relational dataset, which can be categorized in semi-structured or non-structured. If you are dealing with relational datasets, we recommend to go through the lab Databases: MySQL.
- Machine learning algorithms build a model based on sample data, known as "training data", in order to make predictions or decisions without being explicitly programmed to do so. Machine learning algorithms are used in a wide variety of applications, such as in medicine, email filtering, and computer vision, etc. where it is difficult or unfeasible to develop conventional algorithms to perform the needed tasks. If your use case involves machine learning, we recommend to go through the lab Machine Learning: Regression, Machine Learning: Classification, Machine Learning: Clustering or Machine Learning: Time Series Analysis, depending on the machine learning classification of your use case.
The repository is openly available.
Visit the self paced labs repository